
Somewhere in your company's shared drive, or in archived folders that have not been touched in years, there are geological reports that still contain useful information. Historical drill logs, assessment reports, prospect summaries, and consultant memos.
Individually, each of these required significant field effort and cost to produce. Collectively, they represent a large body of geological knowledge that is rarely used beyond its original purpose.
Text mining is one way to start making that information usable again.

What text mining actually is
Text mining, sometimes called natural language processing (NLP) when it gets more sophisticated (technically a tool within text mining), is the process of extracting structured information from unstructured text. Instead of relying entirely on someone to read a report and summarize it manually, you write code that reads it and pulls out the pieces you care about.
For geoscience, that might mean extracting:
- Lithological descriptions and intervals
- Alteration assemblages and intensities
- Structural observations such as foliation, veining, and brecciation
- Assay references and mineralization styles
- Geological interpretations and target concepts
Once that information is structured, you can query it, map it, compare it across hundreds of holes or reports, and feed it into other analyses. Tasks that once required weeks of reading can become much faster and more systematic.

Step 1: Getting text out of PDFs
The first obstacle is usually the PDF. Drill reports are rarely delivered as clean text files. The good news is that Python makes this manageable.
pdfplumber is a good starting point for text-based PDFs, where the text is actually embedded rather than stored as an image:
import pdfplumber
with pdfplumber.open("NI43-101_report.pdf") as pdf:
for i, page in enumerate(pdf.pages):
text = page.extract_text()
if text:
print(f"--- Page {i+1} ---")
print(text[:300])
For scanned PDFs, which are common in historical datasets, OCR (optical character recognition) is usually required. Tools like pytesseract combined with pdf2image can help, although results depend heavily on scan quality. Typed historical reports can work reasonably well. Handwritten annotations and poor scans are more difficult.
Step 2: Cleaning and normalizing the text
Raw extracted text is usually messy. Page numbers end up mid-sentence. Headers repeat on every page. Tables can come out scrambled. In most real workflows, this step takes longer than expected.
A basic cleaning pass might remove excess whitespace and repeated page markers using regular expressions:
import re
def clean_text(text):
# Remove excess whitespace
text = re.sub(r'\s+', ' ', text)
# Remove page numbers (adjust pattern to suit your reports)
text = re.sub(r'\bPage \d+\b', '', text, flags=re.IGNORECASE)
return text.strip()
In practice, this usually needs to be customized. You may need to strip company headers, remove repeated disclaimers, standardize abbreviations, or preserve interval-style text that would otherwise be lost in cleaning. Each company and reporting era tends to have its own formatting habits.
Step 3: Extracting geological entities
This is where text mining starts to become useful. In standard NLP, named entity recognition is often used to identify people, organizations, and places. In geoscience, the same idea can be adapted to identify lithologies, minerals, alteration styles, structural features, assay values, and other domain-specific information.
A simple rule-based approach using geological vocabularies can go a long way:
import re
LITHOLOGIES = ['basalt', 'rhyolite', 'granite', 'diorite', 'schist',
'argillite', 'sandstone', 'limestone', 'skarn']
ALTERATIONS = ['chlorite', 'epidote', 'sericite', 'silica', 'carbonate',
'potassic', 'propylitic', 'argillic']
def find_entities(text, vocab):
found = []
for term in vocab:
if re.search(r'\b' + term + r'\b', text, re.IGNORECASE):
found.append(term)
return found
sample_text = "The interval showed strong chlorite-epidote alteration in a basaltic host."
print(find_entities(sample_text, LITHOLOGIES)) # ['basalt']
print(find_entities(sample_text, ALTERATIONS)) # ['chlorite', 'epidote']
For more advanced extraction, including context, abbreviations, and variable geological language, libraries such as spaCy can support custom-trained models. That is a larger step, but even relatively simple approaches can be useful when applied carefully.
Step 4: Turning it into something useful
Once entities are extracted, you can build a structured dataset. A report can become more than a static document. It can become a record that includes lithologies mentioned, alteration assemblages, mineralization styles, interpreted deposit types, coordinates, project names, or target concepts.
That makes it possible to ask questions like:
- Which historical holes mentioned skarn alteration within 5 km of this target?
- How many reports reference magnetite destruction in this belt?
- What alteration assemblages appear most often near Cu anomalies in this dataset?
These are the kinds of questions that are difficult to answer consistently when information is buried across many disconnected reports.
Step 5: Connecting text to spatial data and geodatabases
The real value starts to show when extracted text is tied back to spatial data.
Many companies already maintain geodatabases containing collars, geology, geochemistry, geophysics, and other exploration data. Text mining provides a way to connect unstructured report content to those existing systems.
For example, a historical report may describe chlorite-epidote alteration near a known structure, mention anomalous pathfinder geochemistry, or refer to mineralization styles in a way that never made it into the core database. If those references are extracted and linked to a project area, coordinate set, or dataset entry, they become queryable alongside the rest of the geological information.
At that point, you are no longer just searching reports. You are querying integrated geological context.
This is where text mining begins to move from an interesting exercise into something operational.
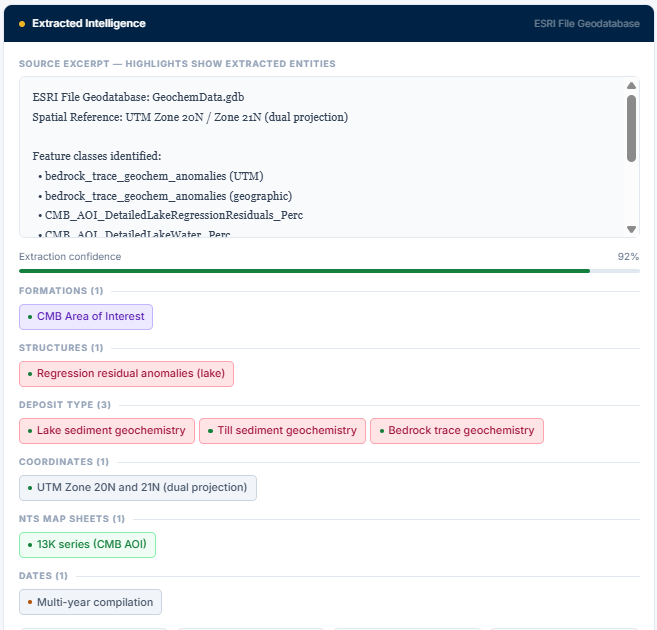
Example demo
I have also put together a small demo showing how this can work in practice, including extraction from scanned reports, native PDFs, Excel datasets, and geodatabases:
View the report text mining demo
The point is not full automation for its own sake. The point is to show how historical data can be moved into a form where it can be searched, reviewed, and used alongside modern datasets.
The honest limitations
Text mining geological reports works best when expectations are realistic. Historical reports are inconsistent. Abbreviations change by author, decade, and company. Terms like "chl-ep alt" and "chlorite-epidote alteration" may refer to the same thing, but your code will not know that unless you tell it.
Every text mining workflow still benefits from geological review. The model or script will miss things, misclassify things, and occasionally misread context. A QA step, where a geologist spot-checks the output, is still important.
Even with those limitations, this approach makes it possible to systematically use information that would otherwise remain buried in old reports. For projects with large historical datasets, that can make a meaningful difference.