
Why Geologists Make Great Data Scientists
There is a generational split in geoscience right now. Junior geologists are excited about machine learning. Experienced geologists, having seen enough silver bullets come and go, are often more skeptical. Both responses are reasonable. This blog exists to build a bridge between them.
A familiar scene plays out at the boundary between geology and technology. A technically strong model gets built, the metrics look impressive, and then somebody notices it is predicting high prospectivity in a place that makes no geological sense. At that point, the geologist in the room quietly loses trust in the entire exercise.
That frustration is understandable, but it hides an important truth: geologists already possess much of what makes someone effective in applied data science. The mental models are closer than they first appear.
You are already most of the way there
There is a well-known way of describing data science as an overlap between three areas: domain knowledge, programming, and math or statistics. It is not a perfect framework, but it is useful. For geologists, one of those circles is already covered: domain knowledge.
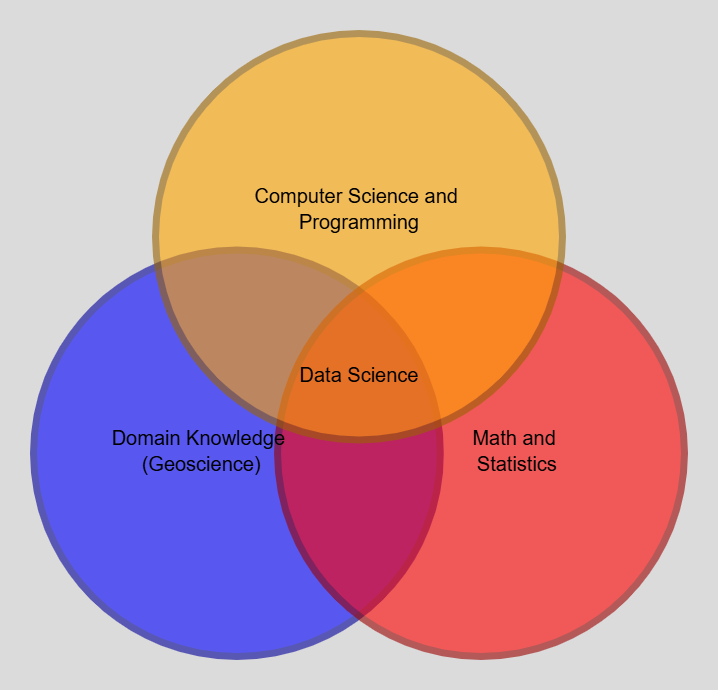
You understand the rocks, the systems, the sampling workflows, and the ways bias enters a dataset long before anyone trains a model. That matters enormously. It is often the hardest part for a generalist data scientist to acquire.
The quantitative side varies by background. Geologists with experience in geostatistics, petrology, resource modelling, or structural analysis often have more statistical intuition than they give themselves credit for. Variability, interpolation, uncertainty, and scale are already part of the job. Even where the formal vocabulary is missing, the habits of thinking are often already there.
For many geologists, programming is the genuinely new piece. That is real, but it is also the most learnable part of the transition.
The gap is smaller than it looks. Geologists often begin with the hardest part already in place: the ability to interpret the world the data came from.
You already think probabilistically
Geological interpretation is almost never about certainty. Contacts, structures, alteration boundaries, grade continuity, and depositional models all come with uncertainty, whether or not it is written explicitly. Geologists are used to working in that space.
That is not a weakness. It is one of the best possible mindsets for applied machine learning. Models do not offer certainty either. They offer probability, confidence, likelihood, and error. A practitioner who is comfortable living with uncertainty is better equipped to use models responsibly.
Pattern recognition is already your core skill
Think about logging core, reviewing maps, or comparing geochemical trends. You are constantly identifying patterns in noisy, incomplete information. You are classifying intervals, noticing associations, and filtering signal from clutter. That is a major part of what machine learning is trying to automate.
The difference is not that the geologist stops recognizing patterns. The difference is that the geologist begins teaching a machine which patterns matter and how those patterns should be represented in data.
Spatial reasoning is a genuine advantage
Many machine learning workflows fail in geoscience because the spatial structure of the data is ignored. Nearby samples are not independent. Drillholes are not random. Continuity is directional. Context matters.
Geologists usually understand this intuitively. They know that two adjacent samples tell a different story than two distant ones. They know that the same anomaly means something different inside a favourable host than outside it. That spatial intuition is not a side benefit. It is a competitive advantage.
You are used to biased and incomplete data
Historical exploration datasets are rarely clean. They are shaped by access, prior ideas, budget, logistics, and old campaign decisions. In machine learning language, that means class imbalance, selection bias, missingness, and inconsistent coverage.
Geologists have been dealing with those realities for a long time. They may not always use data science vocabulary for it, but they know what biased sampling looks like and why it matters.
So what actually needs to be learned?
Mostly Python, some formalization of statistics, and enough machine learning vocabulary to know which tools fit which questions. The geology remains central. In practice, the most useful geoscience ML practitioners are often not generic data scientists who learned a little geology. They are geologists who learned enough coding and statistics to extend what they already do well.
The most useful models in geoscience tend to come from people who understand both the data and the earth it came from.
That is the direction of this blog. The posts ahead will keep the geology front and centre while gradually building the coding and modelling side around it.